Steve Jobs' Commencement Speech at Stanford Graduation Ceremony
Friday, March 9, 2007
Blogspot unblocked
It seems that the ban on blogspot.com has been lifted.
I was surfing, and found a blogspot link, so I followed the chore that I have been following till date:
1.Right click the blogspot link and open it in new tab
2.Press ESC to stop loading the webpage, as it is fruitless
3.Then change xyz.blogspot.com to inblogs.net/xyz and press ENTER
Since I usually open a lot of tabs, so I continued doing my work , and then after some time switched to newly opened tab to do STEPS 2 and 3.
But to my utter surprise , I found that the page was loaded.
So now no more hassles to read your favourite blogs.
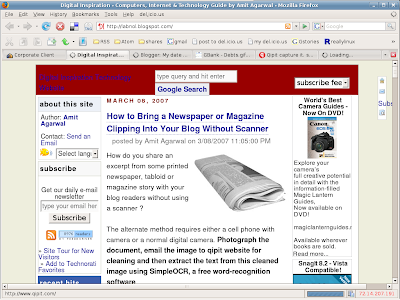 This is a screeenshot of labnol.blogspot.com taken at 02:10 am on March 9th 2007 IST
This is a screeenshot of labnol.blogspot.com taken at 02:10 am on March 9th 2007 IST
I was surfing, and found a blogspot link, so I followed the chore that I have been following till date:
1.Right click the blogspot link and open it in new tab
2.Press ESC to stop loading the webpage, as it is fruitless
3.Then change xyz.blogspot.com to inblogs.net/xyz and press ENTER
Since I usually open a lot of tabs, so I continued doing my work , and then after some time switched to newly opened tab to do STEPS 2 and 3.
But to my utter surprise , I found that the page was loaded.
So now no more hassles to read your favourite blogs.
 This is a screeenshot of labnol.blogspot.com taken at 02:10 am on March 9th 2007 IST
This is a screeenshot of labnol.blogspot.com taken at 02:10 am on March 9th 2007 IST
Thursday, March 8, 2007
Download accelerator for Linux
In my quest to find a download accelerator for Linux, I stumbled upon a lot of download managers and accelerators , like prozilla,prozgui,wxdfast,mget,axel etc etc.
But I couldn't find something at par with IDM or DAP for windows.
Some were refusing to install while others were too slow to be called as download accelerators.
A few days back , one of my friends gave me this amazing tool , called as McURL , which is a shell script to download files in multiple parts via cURL.
To have an idea about the raw power of this script , you can write
$./mcurl -p 100 url_of_file_to_download &
and it will open up 100 threads to download that file
You can also
$./mcurl --help
to see other options
If you are unable to download the file , then please save the following script in a file mcurl and hopefully everything will be ok.
#######################SCRIPT STARTS HERE############################
#!/bin/bash
#
################################################################################
# #
# McURL - A shell script to download files in multiple parts via cURL #
# Copyright (C) 2002 Sven Wegener #
# #
# URL: http://www.GoForLinux.de/scripts/mcurl/ #
# eMail: Sven.Wegener@Stealer.de #
# #
# ---------------------------------------------------------------------------- #
# #
# McURL is free software; you can redistribute it and/or modify #
# it under the terms of the GNU General Public License as published by #
# the Free Software Foundation; either version 2 of the License, or #
# (at your option) any later version. #
# #
# McURL is distributed in the hope that it will be useful, #
# but WITHOUT ANY WARRANTY; without even the implied warranty of #
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the #
# GNU General Public License for more details. #
# #
# You should have received a copy of the GNU General Public License #
# along with McURL; if not, write to the Free Software #
# Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA #
# #
################################################################################
# Some constants
Version="0.1.1b"
# Some defaults which can be overwritten via command-line arguments
DefaultNumberOfParts="10"
# Function to get filesize
function FileSize ()
{
if [ -f "$1" ] ; then
SIZE=`ls -ld "$1" | awk '{print $5}'`
echo $SIZE
else
echo 0
fi
}
# Function to output a warning message
function WarningMessage ()
{
echo -e "Warning: $1"
}
# Function to output an error message and terminate
function ErrorMessage ()
{
echo -e "Error: $1"
exit 1
}
# Output usage information
function OutputUsage ()
{
echo "McURL - Multiple cURL"
echo "Usage: `basename $0` [options...] [URL]"
echo "Options:"
echo " -p/--parts Set number of download parts (Default: $DefaultNumberOfParts)"
echo " -o/--output Set output file (Default: extracted from URL)"
echo " -r/--resume Resume local file (needs \"file.settings\" file)"
echo " -f/--force Force overwriting local file"
echo " -k/--keep Don't delete logfile after download"
echo " -v/--verbose Be verbose (not implemented yet)"
echo " -h/--help Output this message"
echo " -l/--license Output license McURL comes under"
echo " -V/--version Output version number"
echo
echo "If you don't have cURL installed, download it at http://curl.haxx.se/"
exit 1
}
# Parse the command-line arguments
while [ "$#" -gt "0" ]; do
case "$1" in
-p|--parts)
# User wants to set the number of download parts
NumberOfParts="$2"
shift 2
;;
-o|--output)
# User wants to specify a local filename
FileName="$2"
shift 2
;;
-r|--resume)
# User wants to resume a download, so check for it and source the old settings
if [ -e "$2.settings" ] ; then
. "$2.settings"
elif [ -e "$2" ] ; then
. "$2"
else
ErrorMessage "No download to resume"
fi
URL="$OldURL"
shift 2
;;
-k|--keep)
# Keep logfile after download
KeepLogFile="yes"
shift 1
;;
-f|--force)
# Force overwriting local file
Force="yes"
shift 1
;;
-h|--help)
# Output usage information
OutputUsage
;;
-l|--license)
# Show license McURL comes under
echo
echo "McURL - A shell script to download files in multiple parts via cURL"
echo "Copyright (C) 2002 Sven Wegener"
echo
echo "McURL is free software; you can redistribute it and/or modify"
echo "it under the terms of the GNU General Public License as published by"
echo "the Free Software Foundation; either version 2 of the License, or"
echo "(at your option) any later version."
echo
echo "McURL is distributed in the hope that it will be useful,"
echo "but WITHOUT ANY WARRANTY; without even the implied warranty of"
echo "MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the"
echo "GNU General Public License for more details."
echo
echo "You should have received a copy of the GNU General Public License"
echo "along with McURL; if not, write to the Free Software"
echo "Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA"
echo
exit 0
;;
-V|--version)
# Output version information
echo "McURL v$Version"
exit 0
;;
-v|--verbose)
# Enable verbose mode
WarningMessage "Verbose mode not implemented yet."
BeVerbose="yes"
shift 1
;;
-*|--*)
# Unknown option found
ErrorMessage "Unknown option $1."
exit 1
;;
*)
# Seems this is the URL
URL="$1"
break
;;
esac
done
if [ -z "$URL" ] ; then
ErrorMessage "No URL specified. Try --help for help."
fi
# User did not specify NumberOfParts so use the default
if [ -z "$NumberOfParts" ] ; then
NumberOfParts="$DefaultNumberOfParts"
fi
# If FileName is not set extract it from URL
if [ -z "$FileName" ] ; then
FileName="`echo \"$URL\" | sed "s%.*/\([^\/?]*\)\(?.*\)\?$%\1%i"`"
fi
# Still no FileName? -> Seems were retrieveing a directory, so set FileName to "index.html"
if [ -z "$FileName" ] ; then
FileName="index.html"
fi
# Check if file is already there
if [ -e "$FileName" -a "yes" != "$Force" ] ; then
ErrorMessage "File $FileName is already there."
fi
# Fetch header to file
curl --head "$URL" 2> /dev/null | sed -e "s/.$//" > "$FileName.header"
# Check, if header was succesfully retrieved
if [ "$?" -ne "0" ] ; then
rm -f "$FileName.header"
ErrorMessage "Error while retrieving header (cURL return value was $?)."
fi
# Get FileSize from header
FileSize="`grep -i '^\(Content-Length: \)\?[0-9]\+' "$FileName.header" | sed 's/^\(Content-Length: \)\?\([0-9]\+\)/\2/i'`"
# Remove header file since it is not needed anymore
rm -f "$FileName.header"
# If we couldn't get a FileSize, downloading in multiple parts is not possible
if [ -z "$FileSize" ] ; then
ErrorMessage "Failed getting filesize -> File is not downloadable in multiple parts."
fi
# If file was downloaded before, source the old settings
if [ -e "$FileName.settings" ] ; then
. "$FileName.settings"
if [ "$FileSize" -ne "$LocalFileSize" ] ; then
ErrorMessage "Local file has different size as on server -> Resuming is not supported."
fi
else
# Save settings to file
echo "OldURL=\"$URL\"" >> "$FileName.settings"
echo "NumberOfParts=\"$NumberOfParts\"" >> "$FileName.settings"
echo "LocalFileSize=\"$FileSize\"" >> "$FileName.settings"
echo "Force=\"$Force\"" >> "$FileName.settings"
fi
# Calculate RemainingSize & SizePerPart
RemainingSize="$(($FileSize % $NumberOfParts))"
SizePerPart="$((($FileSize - $RemainingSize) / $NumberOfParts))"
# Set Start & End for first part (incl. RemainingSize)
Start="0"
End="$(($SizePerPart + $RemainingSize - 1))"
for i in `seq 1 $NumberOfParts` ; do
echo "Starting cURL #$i for $FileName..."
PartFileSize="$(($End - $Start + 1))"
# Start cURL in sub-shell
(
TempFileSize="`FileSize "$FileName.$i"`"
while [ "$PartFileSize" -gt "$TempFileSize" ] ; do
curl --silent --show-error --range "$(($Start + $TempFileSize))-$End" "$URL" >> "$FileName.$i" 2>> ""$FileName.$i.log""
TempFileSize="`FileSize "$FileName.$i"`"
done
echo "cURL #$i finished..."
) &
# Set Start & End for next part
Start="$(($End + 1))"
End="$(($Start + $SizePerPart - 1))"
done
echo "Waiting for cURLs to finish..."
wait
echo
echo -n "Assembling $FileName... "
# Remove existing file, if Force is set
if [ "yes" = "$Force" ] ; then
rm -f "$FileName"
fi
for i in `seq 1 $NumberOfParts` ; do
cat "$FileName.$i" >> "$FileName" && rm "$FileName.$i"
if [ "yes" = "$KeepLogFile" ] ; then
echo -e "\nLog for cURL #$i:\n" >> "$FileName.log"
cat -n "$FileName.$i.log" >> "$FileName.log" && rm "$FileName.$i.log"
else
rm "$FileName.$i.log"
fi
done
rm -f "$FileName.settings"
echo "Done..."
But I couldn't find something at par with IDM or DAP for windows.
Some were refusing to install while others were too slow to be called as download accelerators.
A few days back , one of my friends gave me this amazing tool , called as McURL , which is a shell script to download files in multiple parts via cURL.
To have an idea about the raw power of this script , you can write
$./mcurl -p 100 url_of_file_to_download &
and it will open up 100 threads to download that file
You can also
$./mcurl --help
to see other options
If you are unable to download the file , then please save the following script in a file mcurl and hopefully everything will be ok.
#######################SCRIPT STARTS HERE############################
#!/bin/bash
#
################################################################################
# #
# McURL - A shell script to download files in multiple parts via cURL #
# Copyright (C) 2002 Sven Wegener #
# #
# URL: http://www.GoForLinux.de/scripts/mcurl/ #
# eMail: Sven.Wegener@Stealer.de #
# #
# ---------------------------------------------------------------------------- #
# #
# McURL is free software; you can redistribute it and/or modify #
# it under the terms of the GNU General Public License as published by #
# the Free Software Foundation; either version 2 of the License, or #
# (at your option) any later version. #
# #
# McURL is distributed in the hope that it will be useful, #
# but WITHOUT ANY WARRANTY; without even the implied warranty of #
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the #
# GNU General Public License for more details. #
# #
# You should have received a copy of the GNU General Public License #
# along with McURL; if not, write to the Free Software #
# Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA #
# #
################################################################################
# Some constants
Version="0.1.1b"
# Some defaults which can be overwritten via command-line arguments
DefaultNumberOfParts="10"
# Function to get filesize
function FileSize ()
{
if [ -f "$1" ] ; then
SIZE=`ls -ld "$1" | awk '{print $5}'`
echo $SIZE
else
echo 0
fi
}
# Function to output a warning message
function WarningMessage ()
{
echo -e "Warning: $1"
}
# Function to output an error message and terminate
function ErrorMessage ()
{
echo -e "Error: $1"
exit 1
}
# Output usage information
function OutputUsage ()
{
echo "McURL - Multiple cURL"
echo "Usage: `basename $0` [options...] [URL]"
echo "Options:"
echo " -p/--parts
echo " -o/--output
echo " -r/--resume
echo " -f/--force Force overwriting local file"
echo " -k/--keep Don't delete logfile after download"
echo " -v/--verbose Be verbose (not implemented yet)"
echo " -h/--help Output this message"
echo " -l/--license Output license McURL comes under"
echo " -V/--version Output version number"
echo
echo "If you don't have cURL installed, download it at http://curl.haxx.se/"
exit 1
}
# Parse the command-line arguments
while [ "$#" -gt "0" ]; do
case "$1" in
-p|--parts)
# User wants to set the number of download parts
NumberOfParts="$2"
shift 2
;;
-o|--output)
# User wants to specify a local filename
FileName="$2"
shift 2
;;
-r|--resume)
# User wants to resume a download, so check for it and source the old settings
if [ -e "$2.settings" ] ; then
. "$2.settings"
elif [ -e "$2" ] ; then
. "$2"
else
ErrorMessage "No download to resume"
fi
URL="$OldURL"
shift 2
;;
-k|--keep)
# Keep logfile after download
KeepLogFile="yes"
shift 1
;;
-f|--force)
# Force overwriting local file
Force="yes"
shift 1
;;
-h|--help)
# Output usage information
OutputUsage
;;
-l|--license)
# Show license McURL comes under
echo
echo "McURL - A shell script to download files in multiple parts via cURL"
echo "Copyright (C) 2002 Sven Wegener"
echo
echo "McURL is free software; you can redistribute it and/or modify"
echo "it under the terms of the GNU General Public License as published by"
echo "the Free Software Foundation; either version 2 of the License, or"
echo "(at your option) any later version."
echo
echo "McURL is distributed in the hope that it will be useful,"
echo "but WITHOUT ANY WARRANTY; without even the implied warranty of"
echo "MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the"
echo "GNU General Public License for more details."
echo
echo "You should have received a copy of the GNU General Public License"
echo "along with McURL; if not, write to the Free Software"
echo "Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA"
echo
exit 0
;;
-V|--version)
# Output version information
echo "McURL v$Version"
exit 0
;;
-v|--verbose)
# Enable verbose mode
WarningMessage "Verbose mode not implemented yet."
BeVerbose="yes"
shift 1
;;
-*|--*)
# Unknown option found
ErrorMessage "Unknown option $1."
exit 1
;;
*)
# Seems this is the URL
URL="$1"
break
;;
esac
done
if [ -z "$URL" ] ; then
ErrorMessage "No URL specified. Try --help for help."
fi
# User did not specify NumberOfParts so use the default
if [ -z "$NumberOfParts" ] ; then
NumberOfParts="$DefaultNumberOfParts"
fi
# If FileName is not set extract it from URL
if [ -z "$FileName" ] ; then
FileName="`echo \"$URL\" | sed "s%.*/\([^\/?]*\)\(?.*\)\?$%\1%i"`"
fi
# Still no FileName? -> Seems were retrieveing a directory, so set FileName to "index.html"
if [ -z "$FileName" ] ; then
FileName="index.html"
fi
# Check if file is already there
if [ -e "$FileName" -a "yes" != "$Force" ] ; then
ErrorMessage "File $FileName is already there."
fi
# Fetch header to file
curl --head "$URL" 2> /dev/null | sed -e "s/.$//" > "$FileName.header"
# Check, if header was succesfully retrieved
if [ "$?" -ne "0" ] ; then
rm -f "$FileName.header"
ErrorMessage "Error while retrieving header (cURL return value was $?)."
fi
# Get FileSize from header
FileSize="`grep -i '^\(Content-Length: \)\?[0-9]\+' "$FileName.header" | sed 's/^\(Content-Length: \)\?\([0-9]\+\)/\2/i'`"
# Remove header file since it is not needed anymore
rm -f "$FileName.header"
# If we couldn't get a FileSize, downloading in multiple parts is not possible
if [ -z "$FileSize" ] ; then
ErrorMessage "Failed getting filesize -> File is not downloadable in multiple parts."
fi
# If file was downloaded before, source the old settings
if [ -e "$FileName.settings" ] ; then
. "$FileName.settings"
if [ "$FileSize" -ne "$LocalFileSize" ] ; then
ErrorMessage "Local file has different size as on server -> Resuming is not supported."
fi
else
# Save settings to file
echo "OldURL=\"$URL\"" >> "$FileName.settings"
echo "NumberOfParts=\"$NumberOfParts\"" >> "$FileName.settings"
echo "LocalFileSize=\"$FileSize\"" >> "$FileName.settings"
echo "Force=\"$Force\"" >> "$FileName.settings"
fi
# Calculate RemainingSize & SizePerPart
RemainingSize="$(($FileSize % $NumberOfParts))"
SizePerPart="$((($FileSize - $RemainingSize) / $NumberOfParts))"
# Set Start & End for first part (incl. RemainingSize)
Start="0"
End="$(($SizePerPart + $RemainingSize - 1))"
for i in `seq 1 $NumberOfParts` ; do
echo "Starting cURL #$i for $FileName..."
PartFileSize="$(($End - $Start + 1))"
# Start cURL in sub-shell
(
TempFileSize="`FileSize "$FileName.$i"`"
while [ "$PartFileSize" -gt "$TempFileSize" ] ; do
curl --silent --show-error --range "$(($Start + $TempFileSize))-$End" "$URL" >> "$FileName.$i" 2>> ""$FileName.$i.log""
TempFileSize="`FileSize "$FileName.$i"`"
done
echo "cURL #$i finished..."
) &
# Set Start & End for next part
Start="$(($End + 1))"
End="$(($Start + $SizePerPart - 1))"
done
echo "Waiting for cURLs to finish..."
wait
echo
echo -n "Assembling $FileName... "
# Remove existing file, if Force is set
if [ "yes" = "$Force" ] ; then
rm -f "$FileName"
fi
for i in `seq 1 $NumberOfParts` ; do
cat "$FileName.$i" >> "$FileName" && rm "$FileName.$i"
if [ "yes" = "$KeepLogFile" ] ; then
echo -e "\nLog for cURL #$i:\n" >> "$FileName.log"
cat -n "$FileName.$i.log" >> "$FileName.log" && rm "$FileName.$i.log"
else
rm "$FileName.$i.log"
fi
done
rm -f "$FileName.settings"
echo "Done..."
Subscribe to:
Posts (Atom)